A Practical Summary of AWS CloudWatch for EXPO
写在前面
AWS CloudWatch 是 AWS 提供的一项监控和日志服务,用于帮助开发人员、系统管理员和运维团队监视其 AWS 云环境中的资源和应用程序,以下是 AWS CloudWatch 提供的主要功能点:
- 监控 AWS 资源:CloudWatch 可以监视各种 AWS 资源,包括 ECS、S3、RDS 等,以便实时跟踪它们的性能指标和运行状况。
- 指标和警报:用户可以在 CloudWatch 中创建自定义指标,并设置警报以便在资源出现问题或超出预设阈值时接收通知。
- 日志管理:CloudWatch Logs 允许用户收集、监视和存储应用程序和系统日志,以便进行分析和故障排除。
- 仪表盘:用户可以创建自定义仪表盘,将不同指标和日志数据可视化展示,以便快速了解系统的运行状况。
- 事件调度:CloudWatch Events 可以监视 AWS 资源的状态变化,并触发相应的自动化操作,例如启动 EC2 实例或执行 Lambda 函数,Event Bridge 也是该服务的衍生服务。
- 日志指标化:CloudWatch Logs Insights 允许用户对日志数据进行实时查询和分析,帮助用户发现潜在问题和优化系统性能。
下面以案例实现的角度,分别阐述在 EXPO 项目中,是怎样使用 AWS CloudWatch 模块服务的。
日志监控
Log Group
在 CloudWatch 中,Log Group 是用来实现日志监控功能的基本概念,一个 Log Group 是多个 Log Stream 的集合。
虽然你可以独立在 CloudWatch 控制面板创建它,但是通常情况下,在创建其他 AWS 服务时,如 RDS、ECS、Lambda 时,Log Group 都是其中必不可少的配置项,在这种情况下,Log Group 会在创建这些服务时,自动创建。
Log Group 在命名规范上,通常有以下约定:
- 建议使用层及目录命名法,如
/expo/ecs/java/customer,但也可以使用任何满足命名规则的名称 - 以
/aws开头的 Log Group 一般是由 AWS 自动创建的 - 对于一些特殊的服务,如 ALB 的 Access Logs,会强制要求使用
/aws/alb开头的 Log Group
Log Stream
Log Stream 即日志流,它对应某个工作负载中实时写入日志的数据流,值得一提的是,Log Stream 通常与工作负载一一对应,如一个 ECS Task,它可能会同时生成多个 Log Stream,这是因为 ECS Task 在高可用前提下,通常是多实例运行的,同时这些 Log Stream,也是彼此隔离的,但它们可以属于同一个 Log Group。
Log Event
Log Event 是日志流中,某个日志事件的可序列化结构,它本身的编码格式是 UTF-8,同时必须要包含 timestamp 属性以及原始的日志信息。
通常情况下,我们不需要花费额外的精力来配置如何发送 Log Event,它们通常会由工作负载中的 CloudWatch Client 自动创建并发送至相对应的 Log Stream,除非在使用 aws-sdk 或者 aws-cli 的场景下。
指标和报警
在 AWS CloudWatch 中,对于异常情况进行监控和通知是通过指标(Metric)和报警(Alarm)实现的。
Metric 是一个标准的可序列化结构,它包含以下几个概念:
- Namespace: 指标命名空间,表示指标属于哪个范畴或服务下的指标,如 RDS、ECS、ALB 等
- Statistic: 用于聚合指标的统计方式,如 SUM、AVG、P95 等
- Dimension: 即维度,它表示一组可唯一标识指标的 key/value 元数据,比如要唯一标识
customer这个 ECS Task,可通过Cluster=expo2025-web,ServiceName=customer来标识 - Period: 用于聚合指标的时间区间,在默认情况下,它的值是 60s,最小值是 1s,如果它大于 60s,则必须是 60s 的整数倍
- Unit: 用于聚合指标的计数单位,比如有些指标统计个数,有些则统计具体的数值
值得注意的是,Metric 本身不是 AWS 资源,它仅仅是一系列用于标记 Log Event 的数据。
Alarm 是一项监控指标的资源,它会在实时监控指标,并在发生异常时触发某个动作,Alarm 包含以下几个概念:
- Metric:用于监控的指标名称,标识指标时,需同时指定指标的 Namespace
- Threshold:触发报警时的阈值
- EvaluationPeriods:标识在几个 Metric 的 Period 内,解析是否触发报警
- Comparison: 触发报警时与 Threshold 进行比较的方式,如大于、小于等
- TreatMissingData:对待指标丢失的时间点的方式,如忽略、发生错误、正常等
Metric 的来源
Metric 可由以下几种方式创建:
- AWS 内置:AWS 服务自动创建的指标
- 各类工作负载相关的指标,如内存、CPU 使用状态、网络吞吐量等
- ALB 的网络吞吐量、请求数等
- 自定义指标:通过
aws-sdk或aws-cli创建- 各类和业务相关的自定义指标,如登录异常个数、超时请求个数等
- Metric Filter:通过关键字匹配的方式,在 Log Group 中创建
- 如 RDS 中的 Slow Query 次数
- 后端服务发生 ERROR 的次数
Alarm 的触发动作
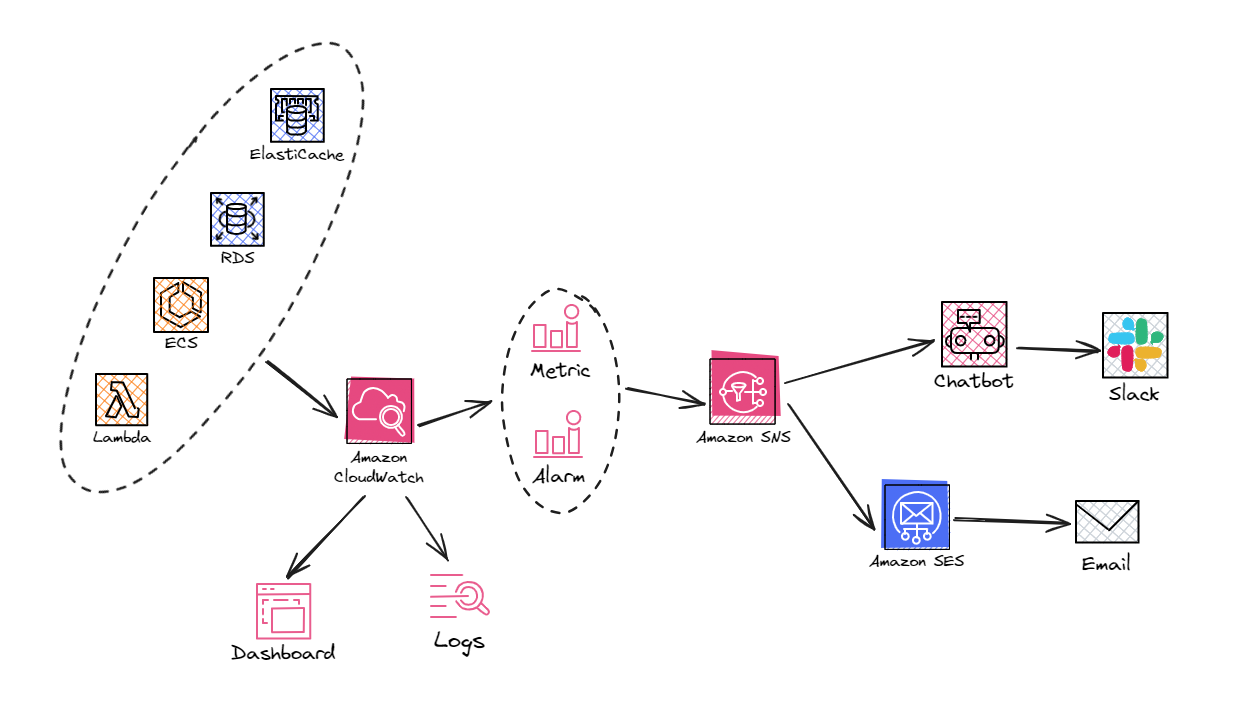
在发生报警时,EXPO 使用 SNS 作为 Alarm 的订阅者,它会订阅报警事件,之后再次将该事件分发给该 SNS Topic 的订阅者,如 Email 或 Slack。
除了通知类的动作之外,Alarm 还支持类似 Auto Scaling 类型的动作,动态地扩展或伸缩工作负载的水平规模,以应对报警事件。
整体架构图